The true cost of poor data quality in banking and insurance
10-minute read
Published on: 23 December 2025
In the Bank of England’s 2024 survey of AI in UK financial services, four of the top five perceived current risks were data-related¹. And the three biggest risks included data privacy and protection, data quality and data security.
That finding reflects a broader reality across large banks and insurers: finance, risk and regulatory reporting are only as strong as the data beneath them. Yet critical information is still spread across fragmented architectures, duplicated between domains and held together with manual reconciliations. The impact shows up in slower closes, higher compliance effort, heavier audit demands and risk metrics that are harder to defend under scrutiny.
So what is the true cost of poor data quality in banking and insurance? And why does it persist even after years of modernization investment?
This article outlines where poor-quality data creates the biggest financial and risk consequences, how regulatory complexity and fragmented systems amplify the problem and why harmonized, well-governed data across domains is becoming a prerequisite for faster reporting, stronger compliance and scalable AI.
The cost of poor-quality data in financial institutions
Data quality underpins core processes in banking and insurance. It spans domains, enabling functions that range from credit-risk modeling and operational-risk controls to accurate underwriting and pricing. Yet even when data quality is not the stated focus, it still plays a major role in decision-making, compliance and financial outcomes.
Consider a Chief Risk Officer (CRO) presenting their bank’s credit-risk position to regulators or the board. The underlying risk models rely on customer, product and transaction data drawn from multiple systems. If that data is duplicated, incomplete, missing or delayed, the model may understate or overstate exposure in certain portfolios. This can cause unexpected losses, flawed capital planning and ineffective hedging strategies.
Even though the discussion isn’t specifically about data quality and focuses on risk metrics, the CRO must acknowledge that every figure depends on the integrity and timeliness of the underlying data.
Poor data quality also increases the audit burden. Financial institutions must not only meet regulatory data-management standards, they must also be able to demonstrate compliance to auditors. This requires clear data lineage, documented data issues and evidence of remediation measures. When data is inconsistent or poorly governed, preparing for audits becomes costly, time-consuming and risky
Despite this recognition of the importance of data, two-thirds of financial institutions struggle with data quality and integration. The challenges banks and insurers most often cite include the following:
Regulatory requirements affect data collection, integrating and reporting
Current regulations heavily dictate data quality in banking and insurance. As financial institutions modernize their finance operations, they also need to comply with increasingly complex and granular regulatory frameworks, such as ESG disclosures, BCBS 239 and Solvency II, that require specific dimensions of data quality (e.g., completeness).
While this kind of granularity poses challenges in data collection and reporting, frequent regulatory changes or updates to current regulatory software only increase reporting complexity and slow down data integration, checks and validations. Recent surveys show that over three-quarters (77%) of financial-services firms anticipate increased regulatory obligations. At the same time, 92% of UK firms report still relying on legacy infrastructure, and devote 70% of IT budgets to its maintenance rather than innovation.
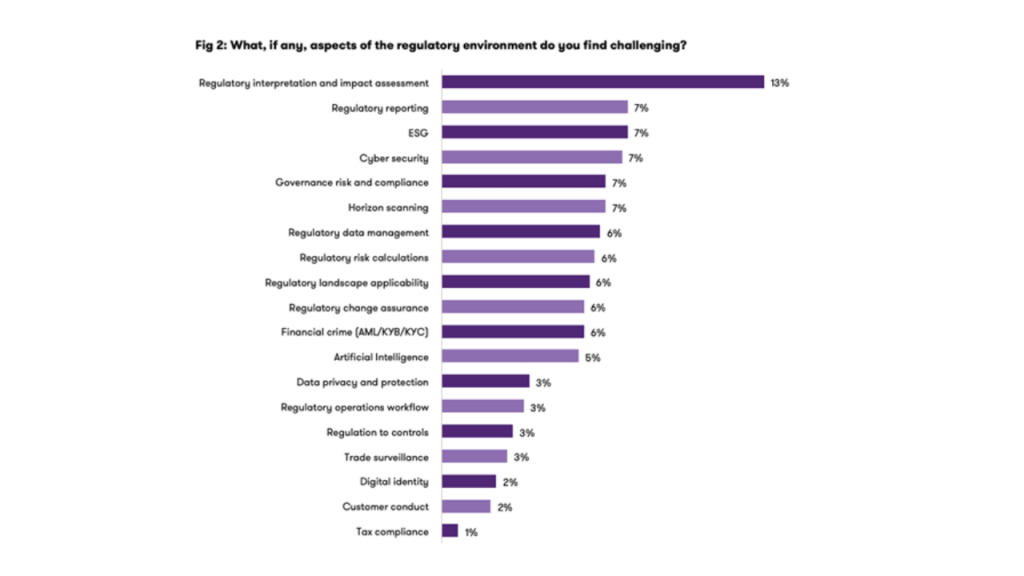
For example, regulatory initiatives like BCBS 239 highlight banks’ obligation to achieve timely, accurate, complete and integrated risk data for both normal and stress conditions. Meeting these standards enables faster risk aggregation and sound capital decisions, while failure exposes firms to supervisory findings, financial penalties and slower crisis response.
Fragmented finance architecture drives cost and compliance risk
While finance-specific regulations demand consistent data logic and traceable financial models, fragmented architectures make that consistency almost impossible. Modernization helps unify accounting, risk and business data, but most finance systems in banking and insurance remain split across legacy solutions, siloed domains and manual workflows.
Integrating, validating and consuming financial data therefore requires deep IT involvement, custom development and frequent reconciliations. Each regulatory change or software update triggers new integration and testing cycles, increasing both time and cost. According to a McKinsey study, financial institutions report that 6–12% of their IT budget goes to data architecture alone, and recognize they could lower that cost by approximately 20% with better models.
This fragmentation prevents banks and insurers from maintaining a consistent solution that connects finance, risk and regulatory data, causing measurable business consequences, such as:
- A rising cost in compliance. Every new reporting requirement, such as revised Solvency II templates or ESG disclosures, requires new mappings and reconciliations across multiple ledgers and data marts. These manual adjustments inflate audit hours, external assurance costs and staff overtime during close cycles.
- Persistent dependency on IT for every schema change, correction or reconciliation, creating long lead times and slowing responses to new reporting or product changes.
- Delays in reporting and closing. Fragmented systems force teams to perform heavy technical and semantic integration work, often supported by manual checks and validations. This means month-end and quarter-end closes increase by days or weeks, delaying management reporting and regulatory submissions.
- Limited data traceability and reuse. Banks and insurers cannot reuse models or audit transformations when they rebuild data logic for accounting adjustments or risk calculations in each application. This weakens transparency and increases model-validation overhead.
- Escalating operational maintenance. Constant interface updates between accounting, risk and reporting tools require ongoing testing and reconfiguration. This raises annual system support and vendor costs.
Integration of new data solutions delays modernization
Incorporating new data sources, analytics, systems and AI-enabled workflows into legacy solutions and fragmented data flows is complex and resource-intensive. Each connection requires custom mapping, validation and testing across different systems. According to a study from the International Journal of Advances in Engineering and Management (IJAEM), 67% of financial institutions say that integrating data across disparate systems remains their largest technological obstacle, limiting their competitiveness.
In insurance, even with strong momentum behind digital transformation, many firms are favoring incremental updates because they see full cross-system integration as too complex and costly.
These delays slow finance modernization, extend project timelines and limit the ability to adopt new regulatory changes or analytical capabilities, which could increase automation.
Poor data quality prevents AI readiness
Financial institutions see AI as a way to automate repetitive tasks and improve decision-making, yet most are not ready to use artificial intelligence effectively. While manual processes and fragmented data architectures increase cost and risk, they also limit AI adoption.
In our FSI forum survey, over half of financial-services respondents said that data quality and integration are the major barriers to enabling and scaling AI. Only a small share cited issues such as skills, budget or regulation.
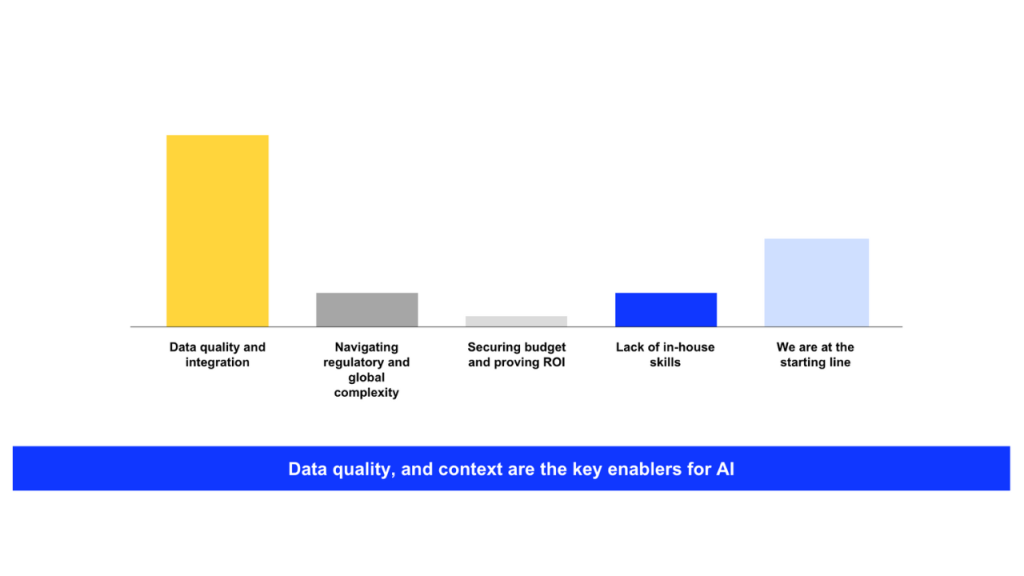
Broader industry data supports this finding. A 2024 study found that 83% of financial institutions lack real-time access to transaction data and analytics due to fragmented systems. When data lives in disconnected spreadsheets, PDFs or legacy solutions, AI agents cannot retrieve or reconcile information consistently.
For example, an AI model trained to assess credit exposure or automate reconciliations cannot do so if customer, risk and transaction data are stored in separate silos. It requires clean, consolidated and standardized data to produce accurate outputs.
Regulators and executives are also raising AI expectations. Both demand audit-ready, explainable AI systems where every recommendation is traceable back to its source data. The World Economic Forum highlights that transparency and traceability of financial data are now essential for regulatory compliance and AI reliability across the global financial system.
Without unified data pipelines and clear governance, banks and insurers will struggle to scale AI beyond pilots or single use cases. Reliable, well-integrated data remains the foundation for trustworthy and compliant AI.
Emerging technologies expose the limits of weak data foundations
Artificial intelligence is only the beginning in modernizing finance in banking and insurance. Tomorrow’s finance workflows will rely on real-time risk simulation, embedded analytics and technologies not yet imagined. All of them depend on a foundation of accurate, complete and auditable data.
Today, AI already powers dynamic stress testing, liquidity modeling and real-time risk analytics, replacing retrospective batch reporting with continuous, data-driven risk management. Financial professionals also increasingly see generative AI (GenAI) as a strategic tool, not just an automation aid.
In a 2024 SAS × Economist Impact survey, 99% of banking executives reported some degree of GenAI implementation, and 89% recognized its value for compliance and fraud prevention. A 2023 Deloitte CFO Signals survey found that over 40% of firms are experimenting with GenAI, and 15% have integrated it into their business strategy.
The same trajectory is visible in embedded analytics, where decision-making is moving inside workflows and interfaces rather than external dashboards. The market for embedded analytics is projected to surpass $60 billion by 2028, showing how pervasive data-driven decision-making is becoming.
Yet this adoption curve hides a deeper challenge. More than half of banking executives report that their early GenAI initiatives delivered limited or no financial return. Weak data integration, inconsistent data quality and fragmented governance are the primary reasons. Emerging technologies cannot compensate for poor data foundations—they amplify the weaknesses already in the system.
Governance risks also intensify as GenAI and AI-driven models connect directly to core finance systems. Institutions must manage model explainability, auditability, cybersecurity and the threat of synthetic or falsified data.
Research shows that advanced architectures—such as graph-based or hierarchical AI models for market forecasting and real-time frameworks using LSTM or Apache Flink—offer new precision and scalability. However, deploying them effectively depends on data that carries context as well as content: standardized metadata, lineage and source integrity.
Without a modern, auditable data foundation, new technologies only add cost and complexity instead of measurable value.
From data debt to decision advantage
For CFOs, CIOs and CROs, poor data quality is a measurable driver of cost, delay and exposure. It shows up in longer close cycles, inflated audit effort, higher compliance burden and risk positions that are harder to explain and defend. And as AI, real-time analytics and more granular regulation become standard, weak data foundations increase control gaps and reduce the return on modernization.
That’s why leading institutions are moving toward multi-domain data foundations that unify finance, risk and regulatory logic with shared controls, lineage and governance. The goal is not a “data program” in isolation, but a consistent, reusable foundation that reduces manual effort, strengthens compliance confidence and enables finance and risk teams to act faster with data they can prove.
Looking to benchmark your current data foundation against pressure points like close, compliance, risk aggregation and AI readiness? Get in touch to discuss the highest-impact areas to standardize, harmonize and govern first.

Related posts

What to demand from a finance data solution built for banks and insurers
Most read posts

Unlocking scalable AI in insurance from the core

Rethinking insurance commission complexity as a strategic advantage

What sets modern policy administration systems apart
More posts
Get up to speed with the latest insights and find the information you need to help you succeed.